En nuestro presente, ya es posible construir una realidad dentro del género del superrealismo, una falsa realidad compuesta por piezas vivas de una apariencia brillante, fascinante y esencial como potenciador de la creatividad artística. Un buen ejemplo de ello es el último vídeo realizado con la técnica deepfake para la campaña publicitaria de Cruzcampo.
El marketing ha encontrado su filón de oro con este avance en el campo del software dentro de la inteligencia artificial. Una de las empresas que ha utilizado esta técnica ha sido Cruzcampo, con su vídeo, emitido en algún medio, en el cual devuelve a la vida a una de las iconos españolas más queridas, Lola Flores. Su título “Con mucho acento”, en él retumba de nuevo su voz para recordarnos algo muy nuestro: el poderío.
La agencia publicitaria que se encuentra detrás del proyecto es Ogilvy y Metropolitana el estudio de postproducción y efectos especiales que lo ha llevado a cabo. Todo ha sido posible gracias a dos herramientas, una es FaceSwap, un software de código abierto basado en TensorFlow, Keras y Python, lenguaje de programación multiparadigma, es decir, programas usando más de un estilo de programación, y la otra, es DeepFaceLab, un segundo software gratuito que usando vídeos o imágenes ya existentes, a través de sus novedosas redes neuronales, permite sustituir las caras en los vídeos. Está alojado en GitHub, plataforma de desarrollo colaborativo, que ha dado lugar a innumerables tutoriales en Internet.
Aquí se puede ver el vídeo antes referido:

Fuente: https://www.youtube.com/watch?v=47AYlU5dbEc&ab_channel=ElIndependiente
Pero antes que nada, hay que poner en situación lo que realmente tenemos entre manos: un mundo virtual creado por ordenador que nos hace reproducir con fidelidad realidades irreales muy exactas para el ojo humano, no analítico.
¿Y cómo se puede hacer esto? Pues tan “sencillo” como entender que estas nuevas herramientas usan un lenguaje de programación que se basa en una serie de algoritmos RGAs (GANs en inglés) que técnicamente son dos redes neuronales generativas que trabajan una contra la otra, es decir, una de ellas, entrena a generador (decodificador), un tipo de red neuronal artificial que se utiliza para aprender codificaciones de datos eficientes de forma no supervisada. Su objetivo es aprender una representación (codificación) para un conjunto de datos, normalmente para la reducción de la dimensionalidad, entrenando a la red para que ignore el «ruido» de la señal, o dicho de otra manera, crear la representación latente del material de origen, la cual contiene la información de rasgos faciales y de lenguaje corporal.
Y la otra red, un discriminador, que reconstruye la imagen a partir de la representación latente que intentará generar, con dicha codificación reducida, una representación lo más parecida posible a su entrada original.
En resumen, un GAN entrena a un generador, en este caso el descodificador, y a un discriminador en una relación adversarial. El generador crea nuevas imágenes a partir de la representación latente del material de origen, mientras que el discriminador intenta determinar si la imagen es generada o no. Esto hace que el generador cree imágenes que imitan la realidad con gran fidelidad, ya que cualquier defecto sería detectado por el discriminador. Ambos algoritmos mejoran constantemente en un juego de suma cero. Matemáticamente crece hasta llegar a un equilibrio, lo que significa que ninguno de los dos puede aprender nuevos trucos y mejorar. Al retarse constantemente y mejorándose el uno al otro, van evolucionando y cada vez son más difíciles de combatir, ya que se corrigen los defectos automáticamente.
 Fuente: https://machinelearningparatodos.com/tipos-de-aprendizaje-automatico/
Fuente: https://machinelearningparatodos.com/tipos-de-aprendizaje-automatico/
Tengamos en cuenta que deepfake es un acrónimo del inglés formado por las palabras fake, falsificación y deep learning, aprendizaje profundo (métodos de aprendizaje automático basados en asimilar representaciones de datos).
Lo curioso es que no es una nueva técnica, sino que lleva utilizándose desde hace ya algunos años en el género cinematográfico del falso documental o mockumentaries; por ejemplo, el retrato superpuesto de Abraham Lincoln sobre el cuerpo de John C. Calhoun (1865, de manera fotográfica), o la narración de La guerra de los mundos, de O. Wells, (1938, en voz).
Desde los años 90, la tecnología deepfake ha sido desarrollada por investigadores de instituciones académicas, y posteriormente, por aficionados en comunidades online. Se conoce en todos los campo posibles: fraudes, pornografía, política, artes, cine y televisión. Un claro ejemplo es Disney, considerado como el mayor utilitario de esta técnica en sus películas, ahorrando coste operativos y de producción, además de tener el modelo de resolución de imagen mucho mayor y produciendo resultados más realistas que los modelos comunes como es el caso de la película Rogue One una historia de Star Wars con la imagen de Carrie Fisher (2016, cinematográficamente).


Abraham Lincoln sobre el cuerpo de John C. Calhoun. Fuente: https://www.alteredimagesbdc.org/lincoln // Escena Rogue One una historia de Star Wars. Fuente: https://www.youtube.com/watch?v=byKy9kGnyvo&ab_channel=Shamook
Pero vamos a ver las costuras y dobladillos de esta técnica del deepfake, como dice Lola en su vídeo. Si se elige el vídeo de Cruzcampo como referencia, en una segunda versión, observaremos en qué consiste el making off y los diferentes pasos que se siguen para su creación:
-
Primero se realiza la extracción de los datos morfológicos originales, a través de los múltiples vídeos de la cantaora (cerca de unas cinco mil imágenes), para que el programa pueda aprender todas las microexpresiones, expresiones y gestos que aparezcan en ellas. Mientras, por otro lado, se realiza un vídeo con una actriz que recrea de manera humana estos gestos tan característicos para hacer el alineamiento.


-
A continuación, se procede al alineamiento de los rasgos faciales del vídeo latente, (decodificador), es decir, los gestos de Lola.


-
Se produce entonces el alineamiento de la imagen latente (original) con la estructura facial de la actriz (discriminador), el software empieza a funcionar rellenando estructuras computacionalmente.

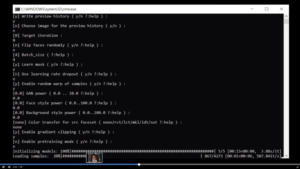

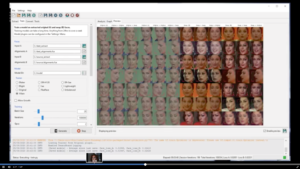
-
Una vez alineadas las dos caras, se ajustan las similitudes mediante el lenguaje de programación. Se unen. Y comienzan los retoques 3D, compositing y efectos visuales hasta llegar al resultado maravilloso.


Obteniendo un resultado final totalmente creíble, como se muestra en este link.

https://www.youtube.com/watch?v=6PU0mOjHQ2U&ab_channel=CULTURA2.0
El trabajo de este programa por unir las expresiones y microexpresiones da auténtico respeto. Ya que al ritmo que avanza esta técnica, ya hay profesionales que se encargan de demostrar que vídeos son fakes o cuáles no.
Nos encontramos ante unos programas informáticos que estudian las emociones y microexpresiones básicas para manipularlas sobre otro ser humano y crear una réplica artificial de algo que es genuino y no repetible de cada uno.
En el lenguaje no verbal, existen diferentes tipos de expresiones como microexpresiones. Las unas dependen de las otras para crear nuestra manera de habla visual. Las primeras son más reconocibles a simple vista, la segundas son tan rápidas como un relámpago y responden a patrones específicos de activación muscular para cada una de estas, que actualmente son capaces de ser reproducidas por algoritmos artificiales de manera casi perfectas al ojo humano no entrenado para detectarlas, y que pueden llevarnos, en un futuro, a desconfiar de toda imagen que se pueda presentar ante un juez sin antes pasar un filtro de análisis forense para detectar posibles estafas y campañas de desinformación.
¿Cómo podríamos estar seguros de que lo que estamos viendo es real o no?
Deberemos poner mucha atención. Y sobre todo ser críticos con todo aquello que llegue a nuestras manos. Para un analista de lenguaje no verbal se debería tener en cuenta varios métodos, para poder diferenciar los patrones repetitivos de expresiones faciales, como por ejemplo: la señal fisiológica del pulso humano, la ausencia o presencia de esta resultante de los cambios en el flujo sanguíneo clasificaría a la persona generada por ordenador o como humana. Como se realiza en el polígrafo, aunque tendríamos que tener el vídeo original para poder analizar los fotogramas de los rasgos faciales. Se podría recurrir también a la técnica euleriana de ampliación de vídeo, con la cual eligiendo un punto del rostro y analizando su variación de luminancia revelaría si existe la variación de color comparable con la del pulso humano o no.
Aunque se han creado nuevos algoritmos que pueden llegar a percibir el flujo de sangre en las personas que aparecen en los vídeos. Otro método que se podría utilizar, es el seguimiento de la posición y la alineación de la cabeza, a través de un logaritmo o manualmente, que analice fotogramas continuos extraídos, en donde deberán coincidir escala y postura teniendo en cuenta la iluminación y el movimiento, ya que el software rellena los huecos con información inventada. La misma técnica se podría utilizar para hacer una medición lineal de unidades faciales de la musculación como las arrugas de la nariz, levantamiento de pómulos, estiramiento de la comisura de los labios, la arruga de las cejas en la expresión de tristeza…
El más interesante y detectable hasta ahora es el parpadeo, el algoritmo aún no está diseñado para realizar esta acción tan rápida como la haría un ser humano (una vez entre 2 a 8 segundos y una duración de 1,4 décimas de segundo). La razón es que muchas de las imágenes de uso común están sacadas de Internet y no se suelen usarse aquellas que tienen los ojos cerrados, por cuestión de estética.
- Otras técnicas de la detección que podríamos observar para detectarlos, en el marco del campo del análisis forense digital, son:
- Efectos de luz extraños en iluminación.
- El movimiento de cabello (suele ser difícil de reproducir).
- La calidad tanto del sonido de la voz como del sonido de fondo: su sincronización entre ruido e imagen. Por cada segundo que una persona habla, su voz contiene entre 8.000 y 50.000 datos que pueden ayudar al ordenador a verificar su autenticidad; por ejemplo, la pronunciación de los sonidos fricativos, como la letra f, ya que a los sistemas de deep–learning les cuesta mucho diferenciar esos sonidos con posibles ruidos.
- Los detalles: hay que estar muy atento a las discrepancias entre las imágenes superpuestas, como el interior de las bocas, un cierto desenfoque en desacorde con la nitidez del rostro, joyas y complementos. Otra fuente de información puede ser el reflejo del iris (un estudio realizado por científicos españoles detectó una precisión final del 87,5 % sobre una base de datos propia).
- Duración del vídeo: al ser trabajos costosos en sus procesos suelen ser de corta duración; por el momento, la tecnología avanza muy rápido.
- Corroborar la fuente: algo obvio saber cual es el origen antes de darlo por verdadero.
- Análisis digital forense de metadatos.
En este vídeo podemos observar muchas cuestiones de las que se ha hablado hasta ahora:
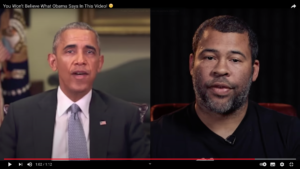
Obama fake. Fuente: https://www.youtube.com/watch?v=cQ54GDm1eL0&ab_channel=BuzzFeedVideo
Algunas empresas tecnológicas ya están financiando investigaciones para trabajos más sofisticados. La plataforma Facebook anunció que no permitirá y eliminará vídeos modificados por AI, como los deepfake. En el ámbito tecnológico, se empieza a crear un debate ético sobre su uso que debería acabar en leyes de protección para las diversas consecuencias que pueda generar toda esta tecnología en usos no correctos. Aunque ya se conocen algunos casos de estafa, y se están tomando medidas, por ahora se necesita de un actor real para poder recrearlos. Pero no todo es negativo, el mundo de las redes es algo realmente fascinante, y nos hace pasar un buen rato viendo perfiles de amigo, memes y demás ocurrencias de uso cómico que hacen que sea una tecnología de lo más divertida. Porque aplicaciones hay muchas para poder jugar con ellas, entre las cuales destacan Zao, Doublicat, AvengeThem… entre otras.
Aquí tenemos dos ejemplos:


El equipo E. Fuente: https://www.youtube.com/watch?v=dj5M4s-cdAw&ab_channel=FaceToFake // J’adore starring Mr Bean. Fuente: https://www.youtube.com/watch?v=tDAToEnJEY8&ab_channel=crookedpixel
No quisiera terminar este artículo sin hablar de un fotógrafo de quien soy muy fan; sobre todo de sus vídeos, me refiero al fotógrafo Brais G. Ruoco que utiliza la app Reface para poner su rostro en todo tipo de películas y cuadros, creando escenas muy divertidas. Esta app para móvil utiliza la tecnología faceswap (intercambio de caras) y es una de las más descargadas en 2020 (más de 40 millones de descargas).





Instagram Brais G . Ruoco. Fuente: https://www.instagram.com/braisgrouco/ // https://www.instagram.com/stories/highlights/17849976902355443/